
Everyone uses ChatGPT, and it’s being utilized extensively across different fields—from coding to writing emails, and even in the film industry to write or improve scripts, which is remarkable. We used to think AI couldn’t achieve such a level of creativity anytime soon, but seeing ChatGPT excel—even completing medical exams with high marks—challenges that belief. However, this remains debatable since ChatGPT occasionally struggles with simple problems that a 7-year-old could solve. Despite these limitations, it’s hard to ignore how impressive ChatGPT is, especially considering how quickly it became popular.
What might amaze you even more is understanding how ChatGPT actually works—how it interprets your questions and crafts such coherent responses.
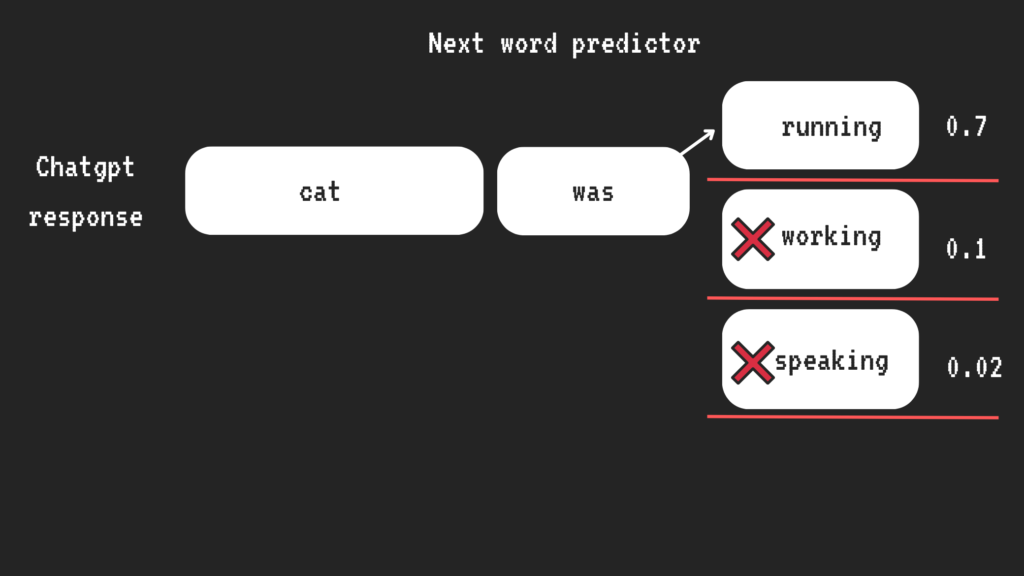
The way ChatGPT works is relatively straightforward on the surface: it’s essentially a “next-word predictor.” It predicts the next word in a sequence while generating responses (more on this later). However, if you dive deeper, the complexity of the systems working together can be mind-boggling. Let me simplify it for you so it’s easier to understand.
How ChatGPT Works
ChatGPT is part of a family of AI models in the field of Natural Language Processing (NLP). Machines cannot inherently understand human language in its raw form. NLP models process our language into a machine-readable format, which is why it’s called ‘natural language processing.’
We’ve been using NLP models for years in tools like Siri on iPhones, Google Assistant, and Google Translate. However, their responses were often very basic and lacked the creativity that ChatGPT now exhibits.
Here’s a simplified breakdown of how NLP and ChatGPT function:
Tokens
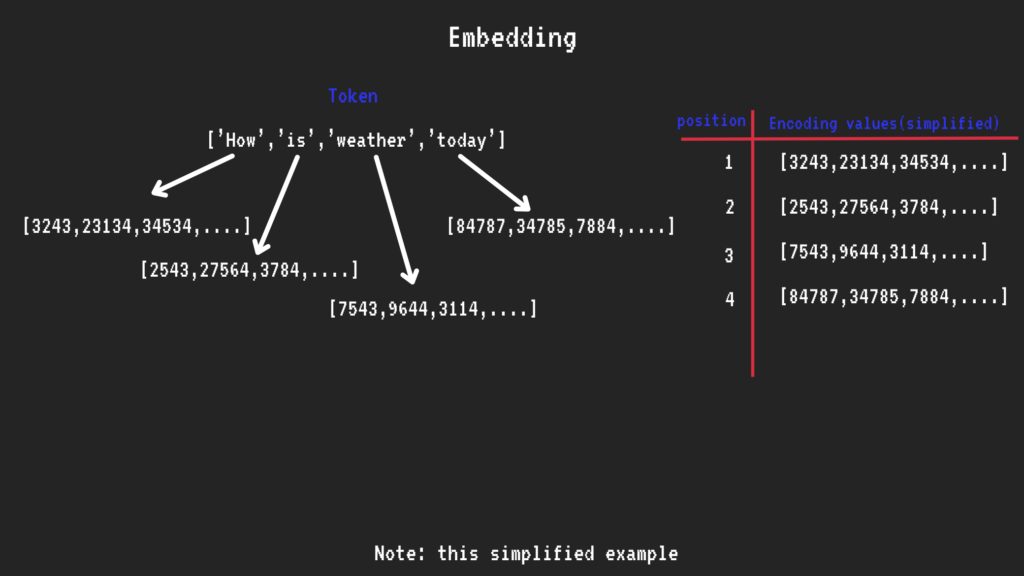
NLP models break down your input into tokens. For example, the sentence “How is the weather today?” would be split into tokens: [“how,” “is,” “weather,” “today”].
Each model has a limit on the number of tokens it can process at once. For ChatGPT, this limit is around 124,000 tokens. However, these tokens aren’t processed in their text form (e.g., “how” or “weather”).

Embedding
The next step is converting tokens into numeric vector values. For instance, the token “how” might be represented as a vector like [1230, 2322, 1263, …].
This concept might be hard to grasp initially, so let me simplify it. Imagine our physical world in 3D space, where we use x, y, and z coordinates to define an object’s position. Similarly, ChatGPT uses vectors to map tokens into a space—but instead of 3 dimensions, it operates in 256 to 1024 dimensions. This is difficult for humans to comprehend since our perception is limited to 3D.
ChatGPT ensures that words often used together are mapped closer in this space. For example, “car” and “door” are more likely to be mapped near each other than “car” and “horse.”

Positional Encoding
Unlike humans, who process language sequentially (one word at a time), AI models process information in parallel. For example, the phrase “How is the weather” is processed all at once, not in order. To maintain the correct sequence of words, positional encoding assigns a value to each token that indicates its position in the sentence.
This ensures that when tokens like “how,” “is,” “weather,” and “today” are processed simultaneously, the model still understands their order in the original sentence.
Why ChatGPT Stands Out
After processing the input, ChatGPT generates its output. What sets it apart is the scale and quality of its training.
ChatGPT has been trained on an extensive dataset that includes content from Reddit, Wikipedia, recipe websites, GitHub, and more. This allows it to understand various aspects of human language, like grammar, context, verbs, and subjects. The more comprehensive and clean the training data, the more accurate ChatGPT’s responses become. However, if the dataset contains errors or biases, the quality of its output will also suffer.
After training, OpenAI fine-tuned ChatGPT to ensure its responses are helpful, neutral, and safe.
How ChatGPT Produces Responses
ChatGPT generates responses by predicting the next word based on your input. It mimics human brain neurons to produce language. Additionally, it incorporates randomness into its responses, which is why answers can vary slightly each time. This randomness is controlled by a “temperature” setting: higher values produce more creative but less reliable answers, while lower values make responses more focused and consistent.
Detailed Step-by-Step Diagram: From Input to Output
1. User Input: [“What is AI?”]
↓
2. Tokenization: [“What”, “is”, “AI”, “?”]
↓
3. Embeddings: [ Vector1, Vector2, Vector3, Vector4 ]
↓
4. Positional Encoding: Adds sequence order information
↓
5. Transformer Layer 1: Self-Attention mechanism processes relationships
↓
6. Transformer Layer 1: Feedforward refines context
↓
7. Transformer Layer 2: Another Self-Attention and Feedforward pass
↓
8. Multi-layer Stacking: Repeats for all Transformer layers (e.g., 12 layers)
↓
9. Output Layer: Predicts probabilities for possible next words
↓
10. Sampling: Chooses the most likely next word (e.g., “Artificial”)
↓
11. Decoding: Converts predicted tokens back to words
↓
12. Final Response: [“AI is Artificial Intelligence.”]
Final Thoughts
Thanks for reading! If you have any questions about ChatGPT, feel free to reach out. I’ll do my best to answer your queries and help you understand it better.